Ein kleines Problem nervte mich schon immer gewaltig. Wenn ich für einen Kunden aus einem PDF das Jahresprogramm in die Website mit Kopieren & Einfügen eingesetzt habe, waren ständig die Umlaute kaputt. Irgendwas stimmte da nicht. Das Wörterbuch erkannte das Wort nicht mehr und die Suche funktionierte auch nicht. Irgendwann wollte ich wissen, warum. Was folgte waren Stunden der Recherche und viele neue Erkenntnisse. In diesem Artikel nehme ich euch mit auf diese Erkenntnisreise …
Dies ist der erste Artikel aus meinem Projekt 52 – in jeder Kalenderwoche wird ab jetzt 1x gebloggt:
Aber zurück zum Thema „kaputte Umlaute“. Ein erster Hinweis war, dass beim Löschen des Umlauts erst die Umlautpunkte verschwanden und der Vokal alleine zurückblieb. Erst beim zweiten Drücken der Delete-Taste verschwand der Buchstabe komplett. Warum denn das? Woran könnte das liegen? Ein Blick in die Datenbank per phpMyAdmin lieferte einen ersten Hinweis:
![]()
Die Umlaute waren nicht da, aber die Vokale gefolgt von %cc%88. Eine Google-Suche später wusste ich, dass dies die hexadezimale UTF-8-Version von Unicode U+0308 ist, dem so genannten „Combining Diaresis„. Also einem diakritischen Zeichen, das so benutzt wird wie der Accent bei einer deutschen Tastatur. Erst kommt der Vokal, dann das Zeichen, welches mit dem Vokal kombiniert wird und Voilà! (Alternativ habe ich den Namen Trema gefunden. Schräg ist, dass die in diesem Wikipedia-Artikel beschriebene Direkteingabe über Alt+u gefolgt von einem Vokal das Problem nicht auslöst.)
Aber warum ist das ein Problem? Der Validator meckert zum Beispiel mit der Fehlermeldung Text run is not in Unicode Normalization Form C.. Dazu kommt die schon erwähnte defekte Suche und Rechtschreibprüfung, aber am schlimmsten war der Abstand hinter dem Zeichen im Firefox:
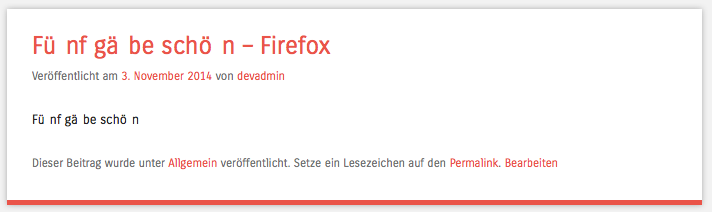
Und noch ein weiteres Problem fiel mir auf. Normalerweise ersetzt WordPress Umlaute durch die entsprechende Kombination mit „e“, also „ü“ wird zu „ue“, „ä“ zu „ae“ und „ö“ zu „oe“. Diese Transliteration war ebenfalls defekt:

Das ist doch ein Bug, der gefixt werden muss, dachte ich mir und schrieb ein Bugticket dazu. Denn der W3C empfiehlt ja, dass überall NFC benutzt werden soll:
This document therefore recommends, when possible, that all content be stored and exchanged in Unicode Normalization Form C (NFC).W3C
Aber was sind das für Normalisierungsformen? Nach dem Lesen des Wikipedia-Artikels bin ich noch nicht wirklich schlauer:
Die vier Normalformen sind: die kanonische Dekomposition (NFD), die kanonische Dekomposition gefolgt von einer kanonischen Komposition (NFC), die kompatible Dekomposition (NFKD) und die kompatible Dekomposition gefolgt von einer kanonischen Komposition (NFKC).Normalisierung (Wikipedia)
Man kann sich das aber ganz gut so merken: NF steht für „Normalization Form“ und „C“ für Combined und „D“ für Decomposed. Die letzten beiden stimmen nicht ganz, die echten Abkürzungen findet ihr hier auf der Unicode-Website, aber so kann ich es mir besser merken … Die anderen beiden Formen NFKC und NFKD sind für uns erst einmal nicht relevant.
Bei Unicode.org gibt es auch eine spannende FAQ zum Thema Normalisierung. Auch hier wird erwähnt, dass NFC die Normalisierung der Wahl ist und in den meisten Fällen angewendet werden sollte.
Aber wie lösen wir das Problem jetzt in WordPress? Dazu habe ich ein Proof-of-Concept gebaut. Ich suche einfach nach den Umlaut-Vokalen gefolgt von der Diaresis/Trema und ersetze es durch den echten Umlaut:
$content = str_replace( "a\xCC\x88", "ä", $content ); $content = str_replace( "o\xCC\x88", "ö", $content ); $content = str_replace( "u\xCC\x88", "ü", $content ); $content = str_replace( "A\xCC\x88", "Ä", $content ); $content = str_replace( "O\xCC\x88", "Ö", $content ); $content = str_replace( "U\xCC\x88", "Ü", $content );
Aber Dominik Schillink (ocean90) wies mich schnell darauf hin, dass dieses Problem für viele, viele andere Zeichen ebenfalls gilt. Eine allgemeine Lösung war das also nicht. Praktischerweise bietet PHP aber in der Version 5.3 eine Funktion, die genau das macht: Normalize. Leider ist diese Funktion nur vorhanden, wenn auch die intl-Extension in PHP geladen wurde, was leider nicht bei allen Hostern der Fall ist. Domainfactory bietet dies zum Beispiel bei seinen Shared Hosting Paketen nicht standardmäßig an. Das Modul kann aber durch eine Anpassung der php.ini zusätzlich geladen werden. (Dazu folgt später ein eigener Artikel.)
Was folgte war ein Normalizer-Plugin, welches prüft, ob die Funktion vorhanden ist und ob der Text normalisiert werden muss. Ist beides der Fall wird der Text normalisiert. Dazu wird die Funktion einfach an die Filter content_save_pre, title_save_pre, excerpt_save_pre und pre_comment_content gehängt. Ich dachte, dass dies eine schöne Lösung ist und lehnte mich zufrieden zurück …
… aber wie das so ist mit Lösungen. Es gibt immer noch mehr Fallstricke und bessere Lösungen. Zum einen gilt das Problem für jedes Inputfeld und nicht nur für die Felder Titel, Inhalt, Auszug und Kommentare. Zum anderen ist der Fehler direkt nach dem Einfügen ja noch vorhanden. Erst beim Speichern wird der Filter angewendet. Pascal Birchler hat das schön in diesem Kommentar zum Ticket zusammengefasst. Eine Möglichkeit dies zu lösen, ist eine entsprechende Javascript-Funktion zu benutzen, worauf mich auch schon Ella Iseulde Van Dorpe in einem früheren Kommentar hingewiesen hatte.
Die nächsten Schritte gehen nun in zwei Richtungen:
Zum einen werde ich das Plugin deutlich erweitern, damit es mehr Fälle in WordPress abdeckt (analog dazu werde ich meinen Core-Patch ergänzen). Dazu werde ich den Callback-Filter für Widgets ergänzen und vor allem die Normalize-Funktion an sämtliche sanitize-Filter hängen. Damit sollte ich die meisten Fälle im Backend von WordPress abdecken.
Zum anderen möchte ich mich mit Javascript auseinandersetzen (laut der State of the word von 2015 ist das sowieso unsere Hausaufgabe 😉 und versuchen per Javascript beim Event des Einfügen („Pasten“) die Funktion auszuführen, so dass der kaputte Text niemals in WordPress ankommt (sofern ein moderner Browser benutzt wird, der diese Funktion unterstützt).
Aber warum tritt dieses Problem überhaupt auf? Bei meiner Suche zu den Themen Normalisierung und Unicode und dieser Umlaut-Problematik bin ich über diesen Rant von Linus Torvald gestolpert, der mich auf die richtige Spur brachte:
And then picking NFD normalization – and making it visible, and actively converting correct unicode into that absolutely horrible format, that’s just inexcusable. Even the people who think normalization is a good thing admit that NFD is a bad format, and certainly not for data exchange. It’s not even „paste-eater“ quality thinking. It’s actually actively corrupting user data. By design. Christ.Linus Torvald
Apple nutzt eine Abwandlung von Normalization Form D bei seinem Filesystem HFS+ und somit auch intern bei solchen Prozessen wie der Zwischenablage. Das Problem tritt häufig auf, wenn Texte aus einer PDF kopiert werden. Diesen Pfad habe ich noch nicht viel verfolgt, warum ausgerechnet PDFs diese Zeichen so an die Zwischenablage übergeben. Vielleicht ist es auch hier Apple welches die Umlaute aktiv kaputt macht. Das kann ich noch nicht sagen. Mehr Infos stehen in QA1173 und QA1235.
Aber das Problem ist nicht auf PDFs beschränkt. Beim Webkrauts-Adventskalender gab es nach einem Artikel von Jens Grochtdreis eine spannende Twitter-Diskussion, wo ich mein neues Nischen-Wissen zu NFC und Co. sinnvoll einbringen konnte:
Die Markdown-Erweiterung des Popclip-Tool hatte NFD statt NFC ausgegeben und so für kaputte Umlaute in Drupal gesorgt.
So kann aus einem kleinen Copy&Paste-Umlaut-Problem ein 6000-Zeichen-Artikel und ein Bugticket werden und das Ende ist noch nicht in Sicht. Andere Ansätze hat das W3C in diesem Wiki-Artikel gesammelt. Zum Beispiel könnten die Input-Elemente im Browser automatisch die Normalisierung durchführen, so dass Drupal, WordPress & Co. das Problem gar nicht lösen müssten.
Du hast auch eine solche Geschichte zu erzählen oder weißt etwas über Unicode, NFC und Co. was hier noch fehlt? Dann ab damit in die Kommentare! Ich freue mich auf euren Input (oder Feedback zu meinem Artikel …)
Krass. Petition gegen NFD? Unterm Strich klingt es ja so, als sollte das Problem wirklich bereits im Dateisystem, spätestens aber im Browser gelöst werden. Trotzdem spannend, die Sache mit dem Feature-Plugin. 👍
Eine so tief sitzende Abhängigkeit im Dateisystem ist wohl sehr schwierig zu ändern, befürchte ich. Aber die Variante mit der Lösung im Browser klingt interessant. Und für unseren Anwendungsfall wäre das der einfachste Weg. Es könnte jedoch sein, dass man aus irgendeinem Grund NFD benötigt und dann wäre es natürlich ungünstig, wenn der Browser eine Zwangsnormalisierung durchführt. Wahrscheinlich werden CMS das Problem intern lösen müssen. Dankenswerterweise gibt es in PHP und JS inzwischen Funktionen dafür. Wir müssen sie nur noch implementieren und darauf warten, dass alle moderne Browser und PHP-Versionen nutzen 😉
Pingback: Internationalization-Modul (intl) nachinstallieren › Torsten Landsiedel
Verstehe ich das richtig? Diese Normalisierung wird nur deshalb benötigt, weil es tatsächlich Programme gibt, die das kleine «ä» nicht als EIN Zeichen abspeichern, sondern als ZWEI Zeichen, ein «a» und ein Trema?
Ich dachte immer, solche «Krücken» wären mit UTF8 hinfällig!?
Ja und leider sind das nicht irgendwelche Programme, sondern z.B. „Vorschau“ von Mac OS X. Ob das jetzt Krücken sind, würde ich bezweifeln, aber warum das jetzt so gewachsen ist, ist in der Rückbetrachtung manchmal sehr schwer zu verstehen …
Pingback: Kaputte Zeichen auf der Website › Torsten Landsiedel
Pingback: United Domains: Zu lange Passwörter nicht erlaubt › Torsten Landsiedel